Ecommerce Catalog Search in the Age of Artificial Intelligence

AI-powered search sounds like the future of ecommerce. In reality, profitable catalog search still runs on boring engineering: a strong dictionary and thesaurus, clean inputs, explicit intent routing, and fast retrieval.
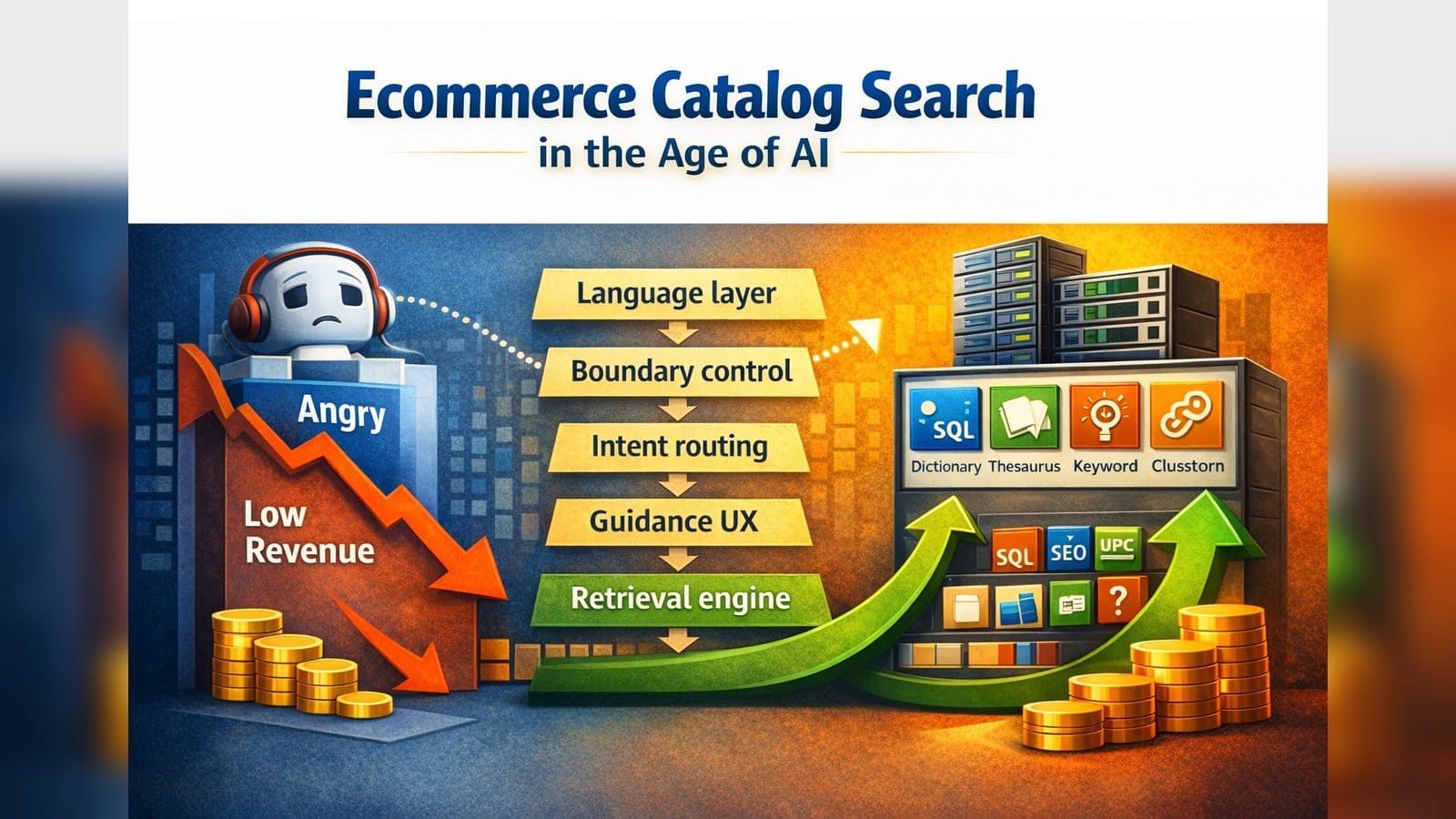
Over time I refined a simple 5-layer architecture that turns catalog intent into orders:
Language layer -> Boundary control -> Intent routing -> Guidance UX -> Retrieval engine.
This is not just a SearchBox feature. The same catalog query engine powers on-site search, navigation, SEO landing pages, and paid traffic landing experiences. When you treat those entry points as one system, search becomes a profit layer - fewer dead ends, fewer zero-result sessions, and better substitutes when items are out of stock.
To keep this write-up readable, I define acronyms first, then the core terms.
Acronyms used in this write-up:
- AI: Artificial Intelligence.
- SEO: Search Engine Optimization.
- SERP: Search Engine Results Page.
- UX: User Experience.
- SQL: Structured Query Language.
- SKU: Stock Keeping Unit.
- UPC: Universal Product Code.
- URL: Uniform Resource Locator.
Core terms used in this write-up:
- Dictionary: our internal list of valid words derived from catalog text (titles and descriptions). We use it for query cleanup and spelling correction.
- Thesaurus: the SQL Server Full-Text Search synonym map (thesaurus files) used for synonym expansion.
- Keyword clusters: intent groups built from Search Engine Results Page overlap. They inform thesaurus strategy, Search Engine Optimization copy coverage, and ads structure.
Architecture Blueprint
Architecture blueprint:
- Layer 0: language layer (keyword clustering and synonym intent groups)
- Layer 1: boundary control (traffic filtering and query sanitization)
- Layer 2: intent routing (classify the query type)
- Layer 3: guidance UX (autosuggest and query refinement)
- Layer 4: retrieval engine (full-text and semantic search)
This order is intentional. Each layer reduces ambiguity and cost for the layers that follow.
Design note: why AI-first search rarely moves profit in ecommerce
AI-first search is often positioned as the next leap in ecommerce. In practice, it rarely creates meaningful incremental profit as the core engine.
Most ecommerce queries are only a few words long. The intent signal is too low for AI to outperform a strong dictionary.
The catalog also changes continuously (new items, renamed items, out-of-stock events, substitutions). Keeping AI grounded becomes ongoing processing cost, while the business outcome is usually marginal.
Chatbot-style search is useful for edge cases, but most shoppers want fast visual choice and quick refinement. AI fits best as a supporting layer, not as primary retrieval and ranking.
A pragmatic view on AI search platforms
The ecommerce search platform market is mature. Many vendors have existed for years, and their core operating model did not suddenly change because the industry started saying Artificial Intelligence louder.
What changed is often the packaging.
A lot of AI-powered search messaging today is a marketing layer on top of the same old reality: indexes, rules, merchandising controls, and a ranking stack that can be hard to reason about from the outside.
As noted above, AI-first search rarely moves profit as the core engine. The more important question is operational: what work still remains even after you buy a platform?
1 - Many published results are hard to compare
Vendor success stories can be directionally useful, but they are often difficult to evaluate across businesses because the measurement context is incomplete.
Common issues are not dishonesty - they are comparability problems:
- unclear baselines and definitions (conversion vs revenue vs margin)
- mixed interventions (search changed together with merchandising, ads, pricing, or assortment)
- no clear time window or cohort definition
That does not mean there is no value. It means you should treat headline percentages as signals, not as proof.
2 - Platforms do not eliminate the real work
Even if you buy a search platform, you still have to build most of the profit-critical layers yourself:
- a language layer (dictionary, thesaurus strategy, clusters, synonym policy)
- boundary control (bot filtering, sanitization, clean telemetry)
- intent routing (query types, identifiers vs categories vs attributes)
- guidance UX (autosuggest, query refinement, mobile-first constraints)
- out-of-stock and substitution logic aligned with your margin model
The platform may provide an engine, dashboards, and knobs - but it cannot remove the need to define your catalog semantics, your constraints, and your operating rules.
3 - The black-box cost shows up in operations
Search is not a demo. It is a production system with failure modes.
When ranking behavior is not fully explainable, improvement cycles get slower. Teams end up tuning symptoms instead of owning the system, and they struggle to connect search changes to measurable profit with confidence.
Our approach is deliberately different: a layered, catalog-native engine that we can measure, control, and evolve. AI is a tool inside the system, not the system.
The trade-off is simple: platforms can accelerate time-to-market, but ownership of behavior and cost discipline is what compounds over time.
With that framing, we start where profitable catalog search starts: the language layer.
Layer 0: Language layer - keyword clustering
If you want ecommerce catalog search to work across SEO, navigation, paid traffic, and the on-site SearchBox, you need a shared language layer.
This is not a nice-to-have. It is the foundation that makes the rest of the system consistent.
For us, that foundation starts with keyword clustering. Even though we built it later in the history of the platform, it is conceptually the right place to start because it feeds almost everything else: thesaurus strategy, query normalization, landing-page intent, and ad structure.
Keyword clustering methods (and why SERP overlap wins)
There are multiple ways to cluster keywords, and each one reflects a different definition of similar.
1 - Lexical similarity (string-based)
Group queries by shared words, n-grams, or edit distance. Fast and simple, but it often clusters similar-looking phrases that have different intent.
2 - Embedding or semantic similarity
Use vector embeddings to group queries by meaning. Useful for general language, but in commerce it can drift because it lacks your market-specific query distribution and real SERP behavior. It may also over-cluster ambiguous terms.
3 - Behavioral clustering
Cluster based on how users behave: clicks, add-to-cart, conversions, refinements. This is closest to truth, but it requires high volume and clean telemetry, which many catalogs do not have for long-tail queries.
4 - SERP-overlap clustering (intent-by-Google)
Cluster queries by overlap of top-ranking URLs. If multiple queries consistently lead Google to the same set of pages, that is a strong proxy that the market (and Google learned behavior) treats them as the same intent.
Why we prefer SERP overlap: it is grounded in real-world intent signals and tends to produce clusters that pass a human sanity check. It is not perfect and needs hygiene (negative keywords, domain typing), but directionally it is the most reliable approach when you want intent clusters that you can actually operationalize.
Keyword clustering from SERP overlap
Synonyms and dictionary-based normalization get much easier when you stop guessing and start using real-world intent signals.
High-level workflow:
- Start with a seed list of keywords from tools like SEMrush.
- For each keyword, fetch what Google shows in the top 10 results (the set of ranking URLs/domains).
- Cluster keywords based on overlap: if multiple results repeat across two queries (for example, 3-4 of the same URLs), we treat those queries as belonging to the same intent cluster.
A note on AI: where it helps and where it does not
Artificial Intelligence is useful in parts of this system, but it is not a reliable foundation for keyword clustering.
Two practical reasons:
- AI does not have your real query distribution. They cannot see how often real shoppers type specific phrases, or which variations truly belong together in your market.
- Google ranking is built on years of observed behavior at massive scale. Using Google as an intent signal gives you clusters that are grounded in reality, and when you sanity-check them, they tend to look directionally correct.
Interestingly, this is where AI can help: not to create clusters, but to classify and summarize what a domain/page is about, so the clustering pipeline can make better keep-or-drop decisions.
A practical challenge: cluster hygiene and SERP interpretation
SERP overlap works well, but only if you keep the clusters clean.
It is not enough to count overlapping URLs. You also need to understand what those URLs represent.
Sometimes Google returns sites that are not relevant to your product universe (aggregators, unrelated informational pages, or results that drift because of ambiguous phrasing). If you cluster on top of that noise, you will merge intents that should never be merged.
What we do to keep clustering grounded:
- Maintain a negative keyword list to exclude queries that are clearly out of scope. In practice, this list tends to be larger than people expect. Typical buckets include:
- Maintain a catalog of common SERP domains and what they specialize in, so we can down-rank or exclude domains that would pollute intent clusters.
In our case, this is not a small list. We have roughly ~20,000 domains categorized and assigned a type and subtype.
- Type is the high-level intent of the domain (informational vs selling).
- Subtype captures the main idea inside that type. For selling domains, it can be who the seller is (retail store, wholesale, manufacturer). For informational domains, it describes what kind of information it primarily provides.
This classification lets us keep SERP-overlap clustering grounded in the right universe of sites, instead of letting unrelated domains merge intents.
A nice side effect: the same negative keyword list can be reused in paid acquisition. Many of these buckets map directly to Google Ads negative keywords, which helps keep ad spend focused on real buyer intent.
What this gives us operationally
We store the clusters in a table that is large, but very manageable for a modern database (in our case, roughly 3.8 million rows) built from about ~58,000 real queries.
That table becomes a practical system component:
- For any phrase, we can retrieve its synonym cluster.
- We can attach frequency signals to synonyms, which helps prioritize which expansions matter.
- We can use those signals to build display and ranking rules (what to show first, when to broaden results, and how to guide the shopper).
Clusters are also valuable for SEO: they help you enrich category and product copy with the right synonym coverage (different words, same intent), which improves relevance without keyword stuffing.
Layer 1: Boundary control - traffic and input hygiene
Once you have a language layer, the next priority is system hygiene.
Catalog search is not only a UX feature - it is also a set of public endpoints. That means you need to control traffic quality and input quality before you spend compute on retrieval.
1.1 Entry points - all are input surfaces
Before ranking, relevance, or UX, there is a boring but critical layer: input hygiene.
And in practice, the very first layer is not string sanitization - it is traffic filtering.
1.2 Traffic quality gate - geo and bot filtering
Search is a public input surface. So the fastest, cheapest win is to reduce bad traffic before it ever reaches your search pipeline.
In my implementation, the first pass is geo filtering and bot filtering using multiple signals (not just a single rule): suspicious geographies for the business, known bad networks, obvious non-human behavior patterns, and request-level fingerprints.
And this is not limited to the SearchBox. The same gate applies to any catalog-query entry point: autosuggest calls, filter URLs, navigation-driven queries, SEO landing URLs, and paid-traffic landing parameters.
This matters for three reasons:
- Performance: you avoid wasting CPU, cache, and database/search capacity on garbage.
- Data quality: you keep search analytics clean, so you improve the system based on real shoppers.
- Security posture: you reduce probing and scanning noise across the entire application, not only search.
Only after that first gate do we normalize and sanitize the raw query string.
1.3 Signature-based query sanitization
We keep this layer intentionally simple and memorable. The goal is not perfect security - it is to keep the catalog query pipeline clean.
At a high level, we neutralize three buckets of garbage:
- Traversal and path probes (including encoded variants) - attempts to smuggle file paths, admin routes, or scanner targets into the query.
- Injection-style payloads - obvious signatures that look like SQL or script probes rather than shopping intent.
- Unsafe characters and control bytes - null bytes, non-ASCII noise, and punctuation patterns that are common in payloads but rarely part of real product intent.
This reduces noise in analytics, protects performance, and lowers the attack surface of every catalog-query entry point.
One operational rule: all of this is enforced server-side. We do not rely on JavaScript for protection, because anyone can bypass the UI and send requests directly.
We also validate request context signals such as the referrer (where the request claims to come from) as an additional layer. It is not a security boundary by itself, but it helps detect and filter obvious non-browser traffic.
1.4 Dictionary-based cleanup
One practical trick that helps both relevance and performance is dictionary-based filtering.
We maintain a dictionary of the words that actually exist in our catalog - pulled from product titles and descriptions.
When a shopper submits a query, the system checks which words in the query are not present in that dictionary and removes them before running the search.
This does two things:
- It reduces noise. Random junk words and bot payload fragments stop polluting the query.
- It makes the remaining query more searchable, which improves retrieval quality and lowers cost.
1.5 Spelling correction - dictionary, Soundex, Levenshtein
Misspelling handling becomes much more reliable when you have a controlled dictionary of valid words.
Instead of comparing a word in the query against the entire catalog text, we compare it against a bounded set of valid terms, which improves both speed and precision.
In our pipeline, we correct in two stages:
- Soundex to quickly produce a small candidate set of dictionary words that sound similar to the word in the query.
- Levenshtein edit distance inside that candidate set to pick the best correction.
This two-stage approach keeps correction behavior consistent and explainable, and it avoids expensive comparisons against the full text universe.
Layer 2: Intent routing - classify the query
If you want catalog search to behave like a profit system, you need a simple truth in your mental model:
Not all queries are the same.
A good search experience starts by recognizing what kind of intent the shopper is expressing, and then responding with the right UX and ranking behavior.
2.1 Exact product queries
These are “I know what I want” queries.
Examples: a specific SKU, model number, part number, or a very specific product name.
A practical nuance: this bucket is harder than it looks.
Sometimes a query is a real product name that exists in your catalog. Sometimes it is a generic phrase. And sometimes it is a product name the shopper saw on another site - meaning it may not exist in your system at all.
What good looks like:
- The exact match is visible immediately.
- Spelling tolerance helps, but does not drown the exact match.
- We try to recognize identifier-style queries (SKU, model number, part number, UPC) using simple patterns and length rules.
- If the query is long enough to look like a product title, we treat it as a likely product-name search first.
- If we cannot find a strong match in the catalog, we widen the net and fall back to semantic search so we can still match “same product, different wording” (for example, when the shopper copied a name from another site).
- If the item is out of stock or not found, we show the closest valid alternatives and guide the shopper toward the nearest in-catalog intent. We also use semantic search here to find the best substitute when the exact item is unavailable.
2.2 Category or group queries
These are “show me the aisle” queries.
Examples: a product family, a group of items, or a broad term.
What good looks like:
- Results behave like a category page, not a random product pile.
- Facets are relevant and complete.
- Ranking is stable, but still reacts to availability and seasonality.
2.3 Attribute and modifier queries
These are category queries with constraints.
Examples: size, color, material, compatibility, price signals, or “for X” usage.
What good looks like:
- Attributes are understood and mapped to structured filters.
- Irrelevant results are aggressively removed.
- You avoid false positives that destroy trust (for example, mixing incompatible variants).
2.4 Assisted-intent queries (keep it simple)
Not every query is a clean product noun.
You will see shoppers type needs, situations, comparisons, brand ecosystems, and compatibility hints.
These are real, but they are not where most stores win or lose profit on day one.
A practical approach is to handle them with lightweight rules:
- Provide a small set of safe, high-confidence matches.
- If intent is unclear, guide the shopper with refinements (facets, suggestions, or a better query).
- Avoid over-interpretation that creates false positives and breaks trust.
The profit-heavy wins usually come from getting exact, category, and attribute queries right first.
Layer 3: Guidance UX - autosuggest and pre-Enter assistance
One of the highest-impact UX upgrades is to help the shopper before they ever hit Enter.
In our SearchBox we use Suggested Queries and, when appropriate, direct product suggestions with images.
The mechanism activates after the shopper types the first three characters. At that point we can already surface highly relevant options and reduce the chance of dead-end searches.
How we order suggestions:
- Suggested queries are ranked by how frequently shoppers use them.
- Product suggestions are ranked by our own popularity and sellability signals, so the first items are not only relevant, but also strong performers.
This matters because it turns search into guided intent capture: faster path to the right result, fewer misspellings, fewer reformulations, and a smoother experience on mobile.
On mobile this becomes even more important. The on-screen keyboard eats a large part of the viewport, so there is very little space for suggestions.
That constraint makes relevance non-negotiable: the first few suggested queries (and products) have to be the best ones, because the shopper often cannot even see more than a handful.
Layer 4: Retrieval engine - SQL Server full-text and semantic search
Search systems often get described in vague terms. So here is the concrete reality of what we use.
At the core, our primary retrieval engine is SQL Server Full-Text Search.
On top of that, we also use SQL Server semantic search capabilities to improve matching beyond exact token overlap.
Why this combination works well in practice:
- It is fast and operationally simple in a SQL Server-centric stack.
- Full-text search handles the high-volume keyword retrieval reliably.
- SQL Server full-text search also lets us maintain a large thesaurus for real shopper language, so common query variations normalize into the same intent.
- Semantic search helps when shoppers use different wording than your catalog, and it provides better candidates for ranking and suggestions.
The point is not that everyone should copy this exact stack. The point is that catalog search is a system: you pick mechanisms that you can operate, measure, and continuously improve.
Conclusion
Ecommerce catalog search is not a feature. It is an operating system for intent.
The system that wins is usually not the one with the fanciest AI demo. It is the one with a clean language layer, strong boundary control, clear intent routing, and fast guidance UX on mobile - all backed by a retrieval engine you can measure and tune.
If you treat search as a profit system, you stop chasing one-off tweaks and start building compounding leverage: fewer dead ends, fewer zero-result sessions, better substitutes when items go out of stock, cleaner analytics, and more demand converted into orders.
Most of the gains come from boring, repeatable engineering - and that is exactly why it works.